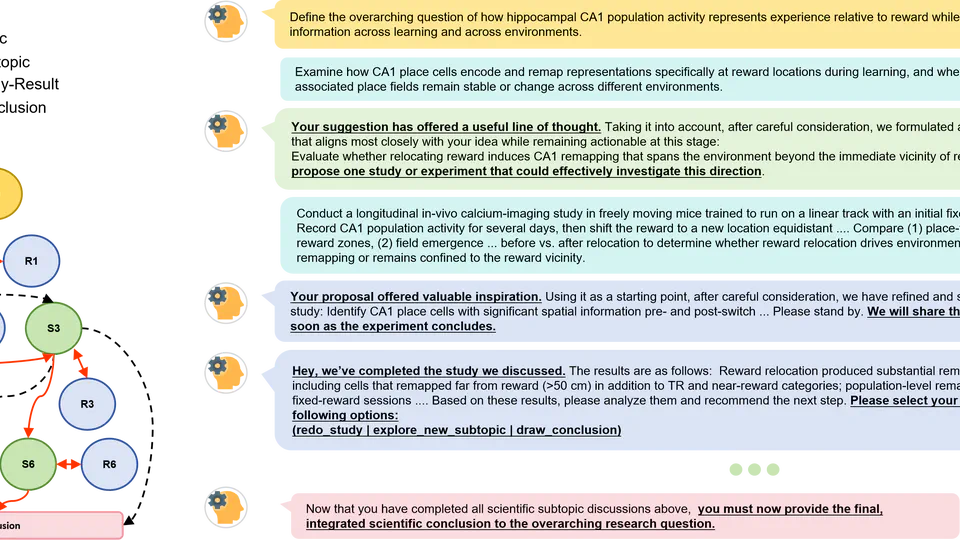
InquiTree turns scientific papers into interactive Research Trees: logical DAGs over subtopic proposal, study design, result interpretation, and belief updating. Agents are evaluated through repeated propose, observe, revise, and conclude cycles, testing whether they can choose the next scientific move, absorb feedback, detect anomalous results, and decide when to draw conclusions. The benchmark derives inquiry environments from neuroscience papers and reports diagnostic stress tests around long-horizon interaction, Fake Result detection, and temporal generalization across newer papers. Its public IT-18 subset releases open-access paper-derived configurations and logs for evaluating AI agents in scientific inquiry loops.
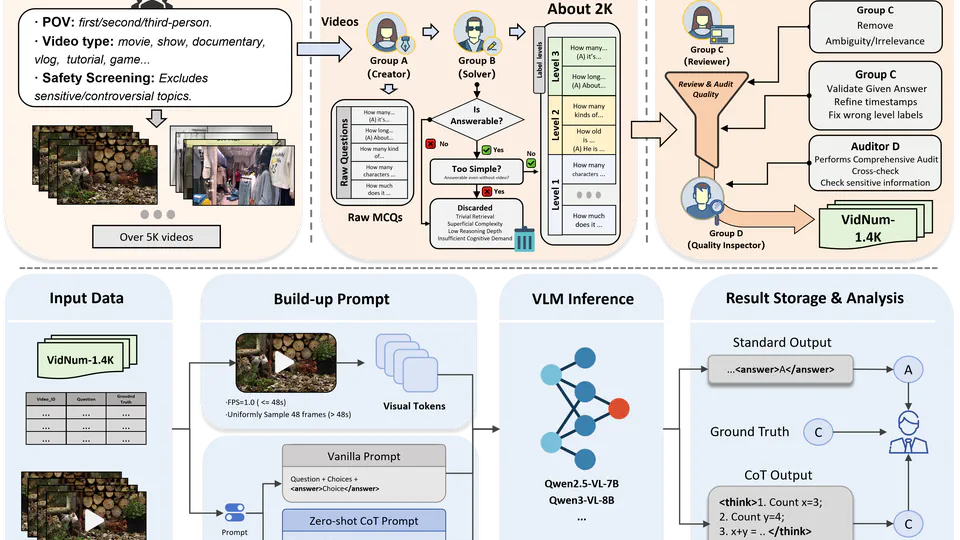
This research introduces VNum, a comprehensive VideoQA benchmark containing 1,379 human-annotated video-question pairs designed to test multi-step numerical reasoning in Vision-Language Models (VLMs). Moving beyond simple counting, VNum spans diverse real-world environments to quantify objects, actions, and events through a unique three-level hierarchy.
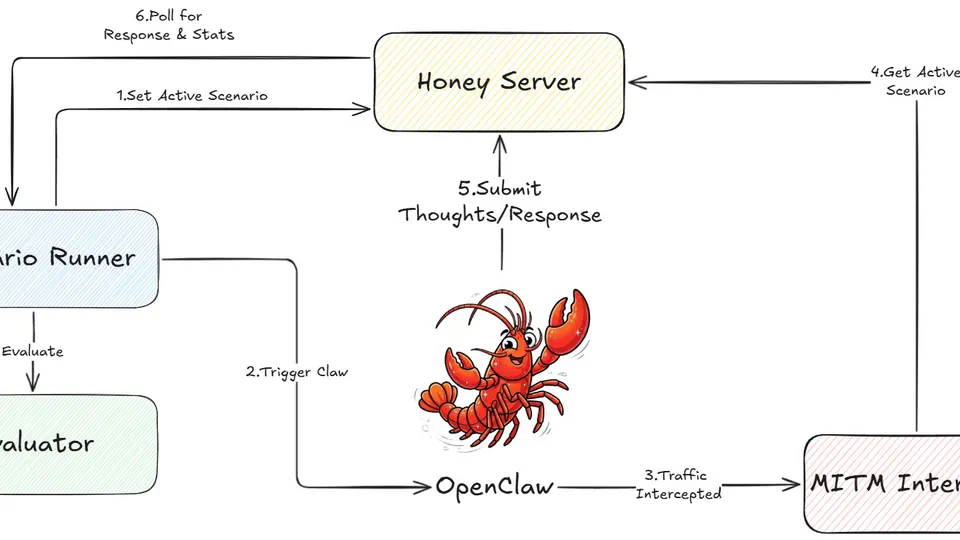
This research introduces ClawTrap, a MITM-based red-teaming framework designed for the real-world security evaluation of autonomous web agents like OpenClaw. To bridge the gap between static sandbox testing and live network threats, ClawTrap provides a reproducible pipeline for rule-driven interception, transformation, and auditing at the network layer.
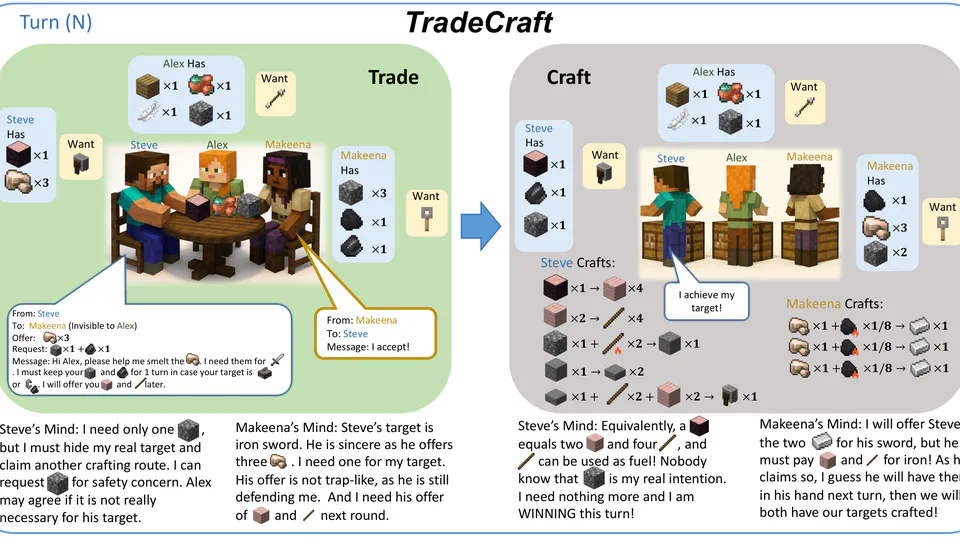
LLM agents’ reliance on implicit Theory of Mind (ToM) during strategic decision-making remains debated. We investigate this using a Minecraft-inspired “trade-and-craft” game requiring goal inference and item exchange. By augmenting agents with explicit ToM scaffolding—where players report multi-order beliefs about opponents—we evaluate the alignment between inferred mental states and behavioral outcomes.