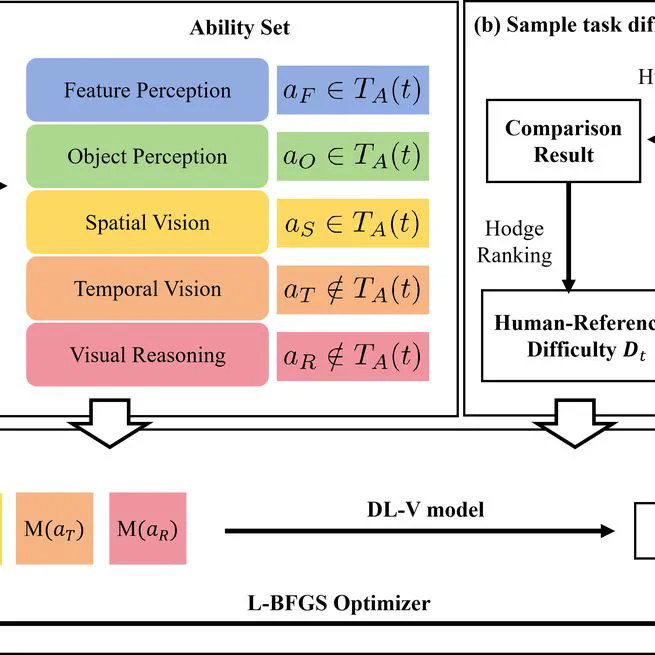
Task Ability Decomposition and Difficulty Quantification of Visual Tasks for AGI Evaluation
First systematic exploration of task-ability space structure and its link to task difficulty. Proposed TADDL-V framework for quantifying visual task difficulty and released AGI-V70 benchmark for AGI evaluation.
Oct 27, 2025

FAB - Factory of Abstract-style Benchmark
Developed the first fully automated, low-cost benchmark generation framework for abstract-style evaluation across general-purpose domains. Enables scalable testing of large language models using structured abstraction errors, covering semantic, structural, and factual variants. Repository: https://github.com/spidermonk7/FAB-Benchmark
Nov 1, 2024